How a Two-Person Team Stopped Asking 'What Did We Decide Again?' and Started Writing Markdown
How a two-person team carried requirements from interview audio to ops announcements—markdown only, in one repo. Shaped by three accidents.
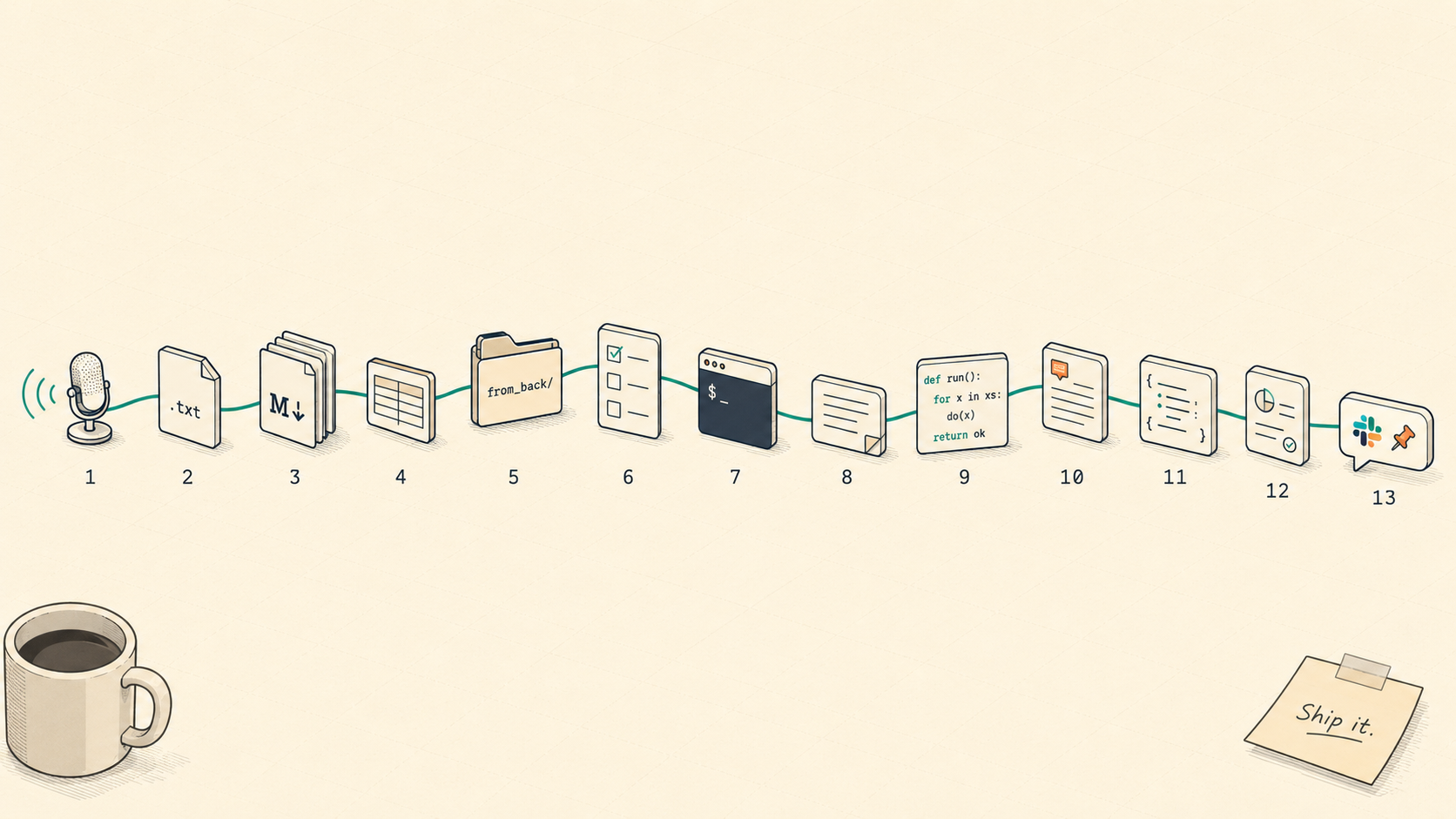
One frontend engineer, one backend engineer. This is the story of how our two-person team learned to chase requirements from a one-hour interview recording all the way to an ops Slack announcement, using only markdown, in a single repository. This post isn't really about code. It's about workflow, and the traceable thirteen-step cycle that didn't grow on a whiteboard but in the middle of three different accidents.
Hi, I'm INSIK, a frontend developer on the BAS KOREA IT Team.
The product we are building, Flow Mate, is a B2B trade operations SaaS that flows from Inquiry → Offer → Order → Logistics → Invoice. If that pipeline is the product side of our work, today's story is about the cycle that runs alongside it: how a comment in a non-developer team's interview eventually becomes shipped code and an ops announcement.
Our development team is two people. One on the frontend, one on the backend. We split PM, BA, QA, and tech-writer duties between us. That made one thing obvious very early: building a workflow on top of human memory is a leaky structure, no matter how you stack it.
This post is probably for you if:
You're on a team of one to three frontend engineers and also wear the PM, BA, or QA hat
You collaborate with AI coding agents (Claude Code, Codex, Cursor, and friends) and your input context shifts every time you start a session
You're tired of hearing the same question in every quarterly planning meeting
1. 'What did we decide again?'
That one sentence echoed across every quarterly meeting room. The decision had been made somewhere, but the reasoning that led to it had vanished. We'd schedule another meeting, re-decide, and then hear the same question again next quarter. The loop was tightening, not loosening.
At the time, requirements were scattered like this:
// Source: in-house retrospective notes, April 2026 (paraphrased)
- Slack #flow-mate-requests: piles up weekly, then gets buried
- Slack DMs: short questions sent privately by an exec, impossible to search later
- Verbal asks in meetings: 'hey, can you look at that next time?'
- Three different Notion pages: nobody remembers who started them
- KakaoTalk group chat: a one-line request from a company dinner
The problem wasn't just that search didn't work. It was something worse, in two parts. First, when the same request landed in two channels, the second person who saw it never knew the first person had already answered. Second, this mess couldn't be handed to an AI coding agent as context. Slack, Notion, KakaoTalk: none of them can be scraped in a single pass. Every cycle, someone had to reconstruct the world from memory.
Someone summarized this whole picture in one line at a team dinner. 'We weren't fragmented because we were only two people. We looked under-staffed because we were fragmented.' Without fewer channels, more people wouldn't have fixed anything.
2. Why we ran toward markdown
Slack DMs looked fastest at first. Then Notion looked the most organized. We spent some time on both. We learned, in the second quarter, that this is the kind of phase you want to end quickly.
So we moved every artifact into markdown files inside a single git repository. Two reasons.
First, git history becomes a decision timeline. Who changed what, and when, is captured automatically. The next time someone asks 'what did we decide again?', the answer is one git log away.
Second, an AI coding agent's working context is the working directory. If your artifacts live somewhere else, you re-scrape and re-paste them every session. If they live in the repo, a single file path will do. The same task feels different when its input is Slack scrollback + meeting notes + audio versus record_data/{date}/analysis-{name}.md + docs/from_back/{feature}/api-spec.md. The second produces stable results; the first wobbles every time.
We gave up the rich views of a hosted knowledge tool in exchange for git history and stable AI input. For a two-person team, that trade almost always pointed the same direction.
3. The 13-step cycle: congealed across rounds, not whiteboards
The cycle was never drawn at once. The folder layout congealed naturally across two or three rounds of interviews. Tracing the repo's timeline backward: on 2026-03-16 the backend first shared an api-spec at the folder level (docs/from_back/2026-03-16-advance-payments-api-spec/); on 2026-03-31 the first seven interview transcripts arrived through ClovaNote; on 2026-04-01 we wedged a superpowers spec into the flow for the first time. The Customer-Merge incident on April 27 cemented front-qna as a standard artifact, and only on 2026-05-08 did the whole cycle get extracted into a single document (docs/process/development-cycle.md). A quarter's worth of accidents, compressed into one file.
The table below is the cycle as it stands today.
| # | Step | Artifact | Driver |
|---|---|---|---|
| 1 | Interview (1:2 or N:2) | record_data/{YYYY-MM-DD}/interview-{name}.txt | FE+BE |
| 2 | Per-interview analysis | analysis-{name}.md | FE + AI |
| 3 | Consolidated backlog | consolidated-interview-backlog.md | FE + AI |
| 4 | Priority and discipline split | FE-only-backlog.md, etc. | FE (human final call) |
| 5 | Sequencing + BE alignment | (Slack ping) | FE+BE |
| 6 | Backend api-spec received | docs/from_back/{feature}/api-spec.md | BE |
| 7 | FE-side spec review | front-qna.md / backend-request-checklist.md | FE + AI |
| 8 | Spec + plan authoring | docs/superpowers/specs|plans/{YYYY/MM}/ | FE + AI |
| 9 | Implementation (TDD) | Code + Vitest | FE + AI |
| 10 | Manual QA | docs/superpowers/qa/{YYYY/MM}/ | FE |
| 11 | Deploy (main → release-deploy) | (branch merge) | FE |
| 12 | Slack ops announcement | No repo copy (the Slack message is the artifact) | FE + AI |
| 13 | Feedback intake | Slack threads / next interview | FE+BE |
The point I want to land is simple: every one of these thirteen nodes maps 1:1 to a real file or folder. It isn't an abstract flow chart; it's an artifact map. Hand me any single line from a production screen, and tracing backward will land on the interview comment that started it in about three minutes on average. That's the cheapest way a two-person team can keep up with a growing user base.
One safety valve, too: we don't run lightweight changes or hot-fixes through all thirteen steps. A change that finishes in an hour collapses into steps 5–7, and a hot-fix goes Slack → code → announcement. But we still leave a plan/QA trace after the fact. Fast tracks are the easiest place to lose traceability.
4. From audio to markdown: five sections of an analysis
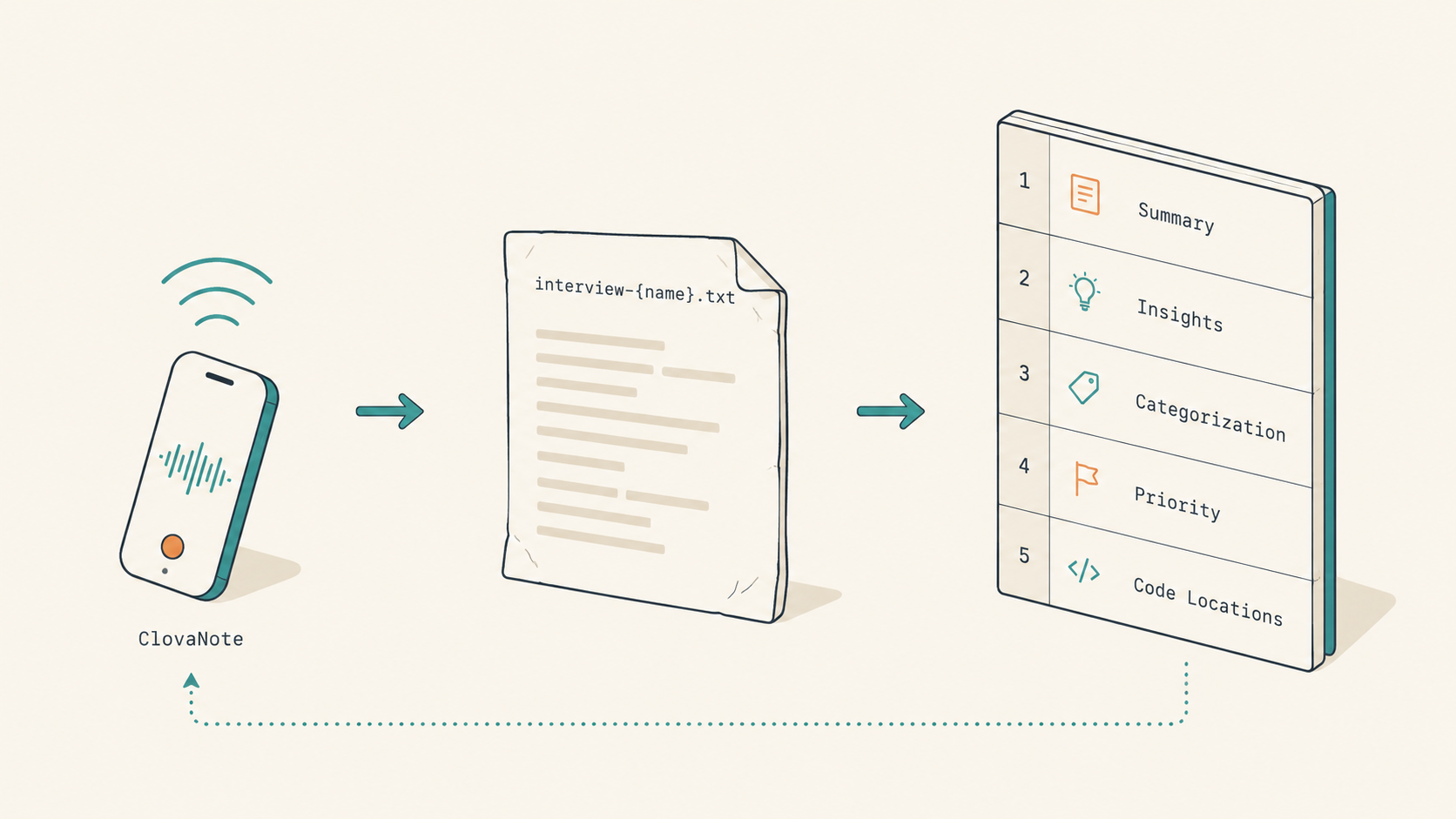
The entry point is plain. We sit down with our non-developer teams (Sales, Logistics, Shared Service) every one to two weeks, either 1:2 or N:2. Naver ClovaNote spits out an automatic text transcript (.txt). We drop the file at record_data/{YYYY-MM-DD}/interview-{name}.txt. Seven interviewees in a round means seven files.
// record_data/2026-03-31/ (actual folder shape, anonymized)
2026-03-31/
├── interview-{nameA}.txt # ClovaNote automatic transcript
├── interview-{nameB}.txt
├── interview-{nameC}.txt
├── interview-{nameD}.txt
├── interview-{nameE}.txt
├── interview-{nameF}.txt
└── interview-{nameG}.txt
Here's the one thing we consciously refuse to do. We do not classify at the audio stage. A single interview mixes feature requests, improvements, bugs, and automation ideas, and if a human tries to listen and classify at the same time, the classifying eats some of the listening. So we capture everything raw and let the next step (the AI step) do the sorting.
That next step is the per-interview analysis markdown. One interview maps to one analysis file. Seven interviews, seven files. We don't merge them yet, because merging is the job of the step after that.
Each analysis markdown has five sections.
| Section | Content |
|---|---|
| 1 | Summary |
| 2 | Key insights (recurring pain points / high-impact improvements / new ideas) |
| 3 | Categorization (bug / template / UX / new feature) |
| 4 | Priority / difficulty / scope (FE / BE / FE+BE) table |
| 5 | Code location candidates (guessed src/... paths) |
The last one is where the magic is. When we hand the analysis to the AI later, those src/... path guesses become instant grep targets. The 'where was this again?' search at implementation time effectively disappears.
// record_data/2026-03-31/analysis-{name}.md (head of the 5-section structure, anonymized)
# Interview Analysis: Sales team member (2026-03-31)
## 1. Summary
...
## 2. Key Insights
- (Pain Point) Inquiry list filters reset after adding a new request (every morning, the team re-applies the same filters)
- (Pain Point) SOA (account receivables) data doesn't line up between FM and the Google Sheet
- (New Idea) Auto-flip to 'Need Reminder' status when a price has been pending more than N days
## 3. Categorization
...
## 4. Priority / Difficulty / Scope
| Item | Priority | Difficulty | Scope |
|---|---|---|---|
| Reset of inquiry filters on refresh | High | Low | FE |
## 5. Code Location Candidates
- src/features/inquiry/.../InquiryListFilters.tsx
- src/features/inquiry/hooks/useInquirySearchParams.ts
We deliberately treat the priority/difficulty/scope column as a first pass, knowing a human will rework it in the next step. Readable single source of truth beats hairline accuracy here.
5. The consolidated backlog and the '× N' impact signal
We bundle the per-interview analyses into one consolidated backlog. A small detail we found here turned out to matter a lot. When multiple people request the same thing, collapsing to one row and listing every requester gives you a free impact signal. No scoring formula required. 'Several people said the same thing' already reads as 'this is impactful' at a glance.
// record_data/2026-03-31/consolidated-interview-backlog.md (excerpt)
| # | Item | Requesters | Priority | Difficulty | Scope |
|---|---|---|---|---|---|
| 1 | Visual cue for fallback FX rate on invoices | Sales × 2 | High | Medium | FE+BE |
| 2 | Persist inquiry filters after refresh | Sales × 3, SS × 1 | High | Low | FE |
| 3 | Debounce on customer search autocomplete | Sales × 2 | Medium | Medium | FE |
This is also the step where we deliberately leave the final call to a human. We read the AI's first pass and override it where needed. 'No, this is a BE item; medium priority is enough here.' There has to be one step where the AI stops, and for us, this is that step.
As rounds accumulate, items get completed, so we refresh an uncompleted-backlog-{YYYYMMDD}.md in the same folder on a regular cadence.
// record_data/2026-03-31/uncompleted-backlog-20260420.md (header excerpt)
> Refreshed weekly. Only carries the open work from the 2026-03-31 round.
> Done items removed; WIP items carry progress + blockers.
| # | Item | Status | Blocker |
|---|---|---|---|
| 14 | Replace invoice PDF logo | WIP | Waiting on final asset from design |
| 17 | Inquiry attachment retention period | DONE | — |
Once that refresh loop is running, interview comments stop silently dropping out.
6. 'What did we decide again?' (the line front-qna retired)
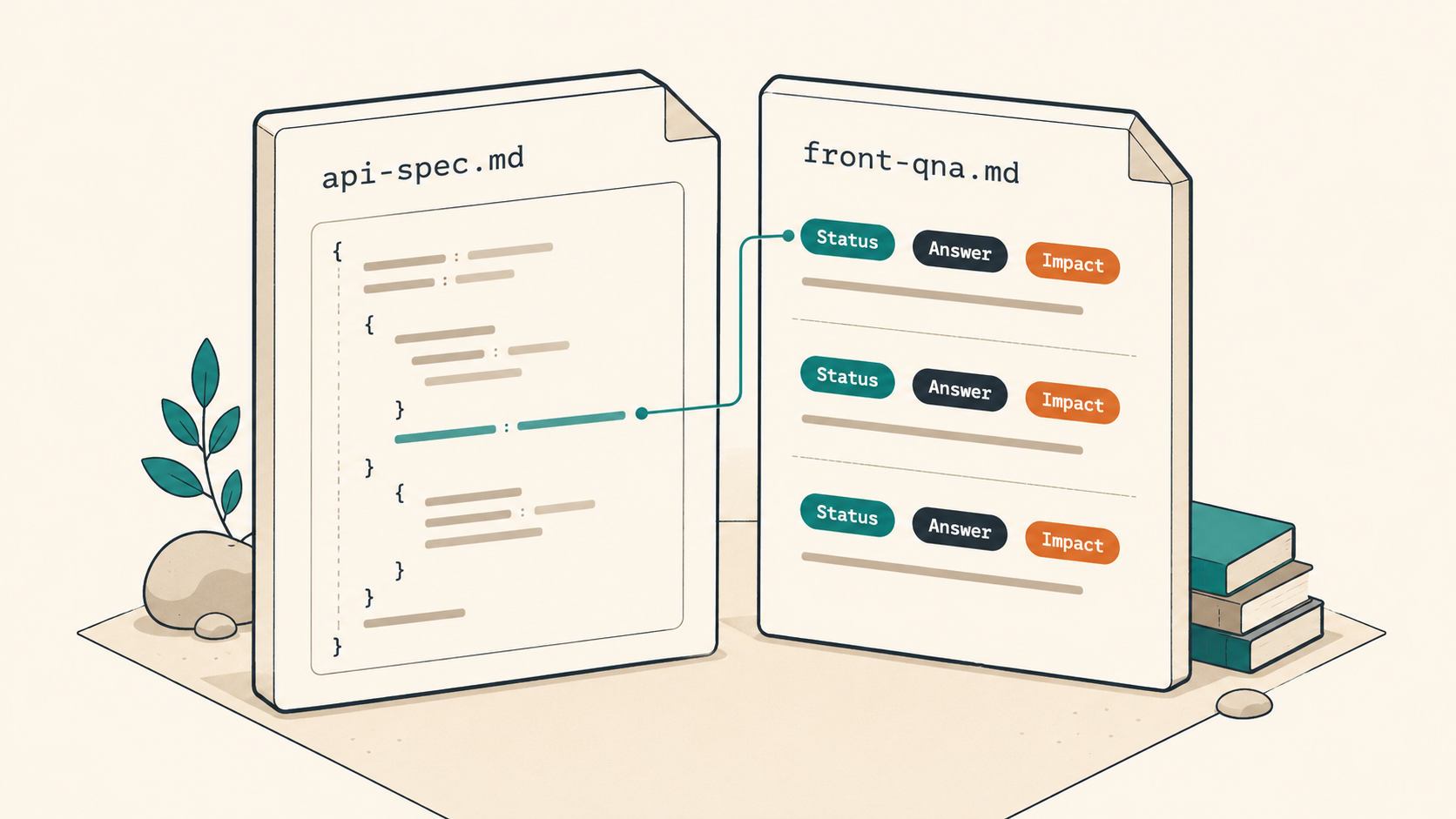
This is, in my reading, the single highest-leverage step in the whole cycle.
When the backend shares docs/from_back/{feature}/api-spec.md by feature, our FE-side AI agent reads it and writes the questions, gaps, and concerns into one file. Lightweight cases go into front-qna.md as Q&A; bigger features go into backend-request-checklist.md. Both live in the same feature folder.
We used to skip this step. 'The api-spec is in, just go straight to spec → plan → implementation.' In late April 2026, we did exactly that on the Customer-Merge feature and ended up reworking the frontend migration flow twice. The ADMIN permission handling and the references response shape didn't quite line up with our assumptions. Right before the second attempt, we ran items 2 through 5 back through a front-qna and pinned every answer inline. Since then we've enforced this step even on small features.
// docs/from_back/2026-04-27-Customer-Merge/front-qna.md (paraphrased excerpt)
## Q2. references response shape
- Question: does response.references[] cover inquiry/order/invoice all together?
- Status: confirmed
- Answer (BE): inquiry + order + invoice + advance_payment (4 kinds). No pagination.
- Impact: add an advance_payment column to the frontend migration preview card.
## Q3. ADMIN permission handling
- Question: what status code does a regular user get (401 or 403)?
- Status: confirmed
- Answer (BE): 403 (authenticated but unauthorized).
- Impact: differentiate the toast copy in useApiErrorHandler when status is 403.
Three small details make this pattern work. First, every item carries a status badge (confirmed / open / follow-up), so anyone glancing at the file instantly sees where the conversation stops. Second, answers don't live in a separate file. They sit inline, on the line below the question. Distance between a question and its answer becomes meeting time, every time. Third, the 'Impact' line is mandatory. A one-liner saying where this answer changes the frontend feeds directly into the next step (spec/plan) without translation.
If you try to do this through meetings, 'what did we decide again?' keeps coming back. With this file in place, both sides look at the same text, and the reasoning behind every decision lives in the repo permanently. The cost of skipping api-spec QA was always higher than the cost of running it.
7. Why we deliberately split spec and plan

With a confirmed api-spec in hand, we bundle the matching consolidated-backlog item and the original interview comments into two artifacts: a spec and a plan. Both live under the superpowers folder, and they're deliberately kept apart.
| Artifact | Skill | Folder | Covers |
|---|---|---|---|
*-design.md (spec) | superpowers:brainstorming | docs/superpowers/specs/{YYYY/MM}/ | Background / best practice / scope (in & out) / UX / data flow / edge cases: what & why |
*.md (plan) | superpowers:writing-plans | docs/superpowers/plans/{YYYY/MM}/ | Goal / architecture / tech stack / file structure / Task 1..N: how, at the file level |
Why not just merge them? Because the moment they fuse, the plan gets fat and the AI agent loses mid-plan context. The reasoning behind the later tasks starts to drift. So when a plan would exceed eight tasks, we go back to the spec step and shrink the scope. Sometimes the plan itself gets split into two files.
// docs/superpowers/plans/2026/04/2026-04-03-confirm-logistics-multi-receipt-upload.md
## Task 3. Add uploadReceiptsSequentially helper (TDD)
- [x] failing test: calls run sequentially, not in parallel
- [x] failing test: keeps going even if one upload fails
- [x] implementation: for-of + try/catch returning PromiseSettledResult
- [x] confirm pass: npx vitest run confirmReceiptUploadUtils.test passes
- [x] swap callsite: LogisticsConfirmModal.tsx
Every task in a plan follows the same three-checkbox shape: failing test → implementation → pass confirmation. Even without an explicit TDD mandate, a checkbox numbered 1 that says 'failing test' pulls the work into TDD on its own. And these checkboxes are the single source of truth for progress. The AI agent doesn't write status reports. When every box reads - [x], the feature is done; an unchecked box is, almost by definition, latent unfinished work.
The lesson here was that an AI's context limit isn't the model's limit. It's the amount we pour into a single shot. Just because you can hand over everything doesn't mean you should.
8. Implementation, manual QA, deploy: the short last three squares
For implementation we pick one of two skills. When independent tasks can be dispatched in parallel inside the same session, we use superpowers:subagent-driven-development; when we want review checkpoints in a separate session with a single flow, we use superpowers:executing-plans. Either way, the plan file's checkboxes stay the single source of progress.
Right before a larger deploy, we write a manual QA checklist under docs/superpowers/qa/{YYYY/MM}/.
// docs/superpowers/qa/2026/04/2026-04-13-ops-release-manual-qa.md (header excerpt)
# Ops Deploy Manual QA (2026-04-13)
## Pre-conditions
- Environment: stage.flowmate.bas-korea.com
- Account: ops-qa-1 (READ_WRITE)
- Data: 50 invoices from March, 12 inquiries from week 1 of April
## Code paths per changed feature
- Inquiry filter URL sync: src/features/inquiry/hooks/useInquirySearchParams.ts
- Invoice FX rate badge: src/features/invoice/components/InvoiceRateBadge.tsx
## Scenarios
- [ ] Apply filter on inquiry list → refresh → same filter persists
- [ ] Yellow badge appears on invoice rows when FX rate falls back
- [ ] Network tab: PUT /color 200, DELETE /attachments/{id} 204
QA checklists are organized by feature, not by date. Date-based files force us to re-write the same scenarios next round. One file carries pre-conditions (environment / account / data), the code paths touched, and the network calls to confirm (PUT /color, DELETE /attachments/{id}, etc.).
Deployment flows from main into the release-deploy branch. The very last square is the Slack ops announcement, and we deliberately do not keep a copy in the repo. The reason is single-pointed: the audience is the non-developer ops team, and non-developers don't read git; they read Slack. We keep the source of truth where the audience lives. If preservation matters, the Slack permalink rides along on the PR body or merge commit.
9. Does TDD apply to markdown too?
TDD lives in code, not directly in markdown. But each artifact carries a self-verification checklist that does the equivalent job.
| Step | Self-check |
|---|---|
| Analysis markdown | Are all five sections present? Does every item carry priority/difficulty/scope? Is there at least one code-location candidate? |
| Consolidated backlog | Is the same request split across two rows? Does the requester column include × N? |
| front-qna | Does every item have 'Status', 'Answer', and 'Impact' lines? |
| spec | Is the scope (in/out) explicit? Is there an edge-case section? |
| plan | Is the first checkbox of every task a failing test? Are tasks at eight or fewer? |
| QA | Do pre-conditions (env/account/data) exist? Are the network calls to verify listed? |
Tests verify code, but they can verify artifacts the same way. Paste the checklist at the bottom of the markdown, and the same bar holds for the next round too.
10. The cycle grew out of accidents: three pitfalls
The cycle looks clean on paper today, but two of its three reinforcing steps were added after we tripped. It grew out of accidents, not whiteboards.
| Incident | Symptom | Regression guard |
|---|---|---|
| Skipping front-qna on Customer-Merge (2026-04-27) | Mismatch between ADMIN permission handling and the references response shape forced the frontend migration to be redone twice | front-qna or backend-request-checklist required on every change, even small ones |
| Plan with 20+ tasks | AI agent loses mid-plan context once tasks exceed roughly twenty | Split the spec when tasks would exceed eight; split the plan into two files if needed |
| Delayed interview analysis | Audio files lose context with time. The 'mood when they said that' fades, and priority calls drift | 'Analysis within 48 hours' rule. If delaying, drop at least one-line notes at the end of the interview .txt while listening back |
The first one was the biggest. We took the api-spec.md straight into spec → plan → implementation, and only right before the second attempt did we walk items 2–5 back through a front-qna and pin every answer inline. After that, even small features were locked into this step. The cost of skipping api-spec QA was always higher than the cost of running it.
The third one is worth a beat too. AI does not interpret audio. Its input ends at the text we wrote down, at the moment we wrote it down.
11. After the cycle settled: what disappeared
| Metric | Before | After |
|---|---|---|
| 'What did we decide again?' meetings | 1–2 per week, 10–20 min each | Virtually gone (front-qna becomes the review surface) |
| Production line → interview comment trace | Untraceable, or 30 min to a few hours | ~3 minutes on average |
| New-joiner onboarding | Inferring why from code alone | Read record_data/ → docs/from_back/ → docs/superpowers/ to reach interview-level reasoning |
| AI context tokens | Re-scraping Slack/Notion every round | Only the step's input file goes into context |
| Requirement loss | Working off whatever requests you remembered that quarter | Consolidated → priority split → uncompleted-refresh loop blocks silent drops |
The first thing that vanished, once the cycle settled, was the sentence we used to hear every quarter. With answers and impact lines pinned inline inside front-qna, the file itself became the review surface, and the question simply stopped showing up in meetings.
The second change is a three-minute traceability budget. Hand me any single line from a production screen, and I can trace back through plan → spec → api-spec → interview comment in about three minutes. A future teammate joining the project can read in the order record_data/ → docs/from_back/ → docs/superpowers/ and reverse-engineer why any piece of code looks the way it does, all the way back to the interview that triggered it.
The third is AI cost. Because each step has a tightly scoped input file, we stopped re-burning the same context every time. The token bill that used to come from scraping Slack and Notion every cycle just stopped growing in lockstep with our feature count.
Being able to answer why this code from a single production line is, in the end, the cheapest way a two-person team can keep up with a user base that's growing faster than headcount.
12. The one-page tool and skill matrix
| Step | Tool / Skill |
|---|---|
| Interview recording / transcription | Naver ClovaNote (speaker separation + summary assist) |
| Interview analysis / consolidation / classification | Claude Code (claude-opus-4-7) |
| Backend spec review | Claude Code (writes backend-request-checklist.md / front-qna.md) |
| Spec authoring | superpowers:brainstorming |
| Plan authoring | superpowers:writing-plans |
| Implementation | superpowers:subagent-driven-development or superpowers:executing-plans |
| Unit testing | Vitest (/** @vitest-environment jsdom */ required for DOM tests) |
| Manual QA | In-house checklist + network tab |
| Release announcement | release-announcement skill (one-shot output posted to Slack) |
| Commit messages | commit-message skill (Conventional Commits) |
13. Closing: we didn't run to markdown because we were short on people

If I had to compress today's story to its frame, it's four things.
Shrink the request channels. Leave Slack, Notion, DMs, and memos as they are, and adding people won't seal the leaks. A one-hour interview plus a single ClovaNote .txt as the only entry makes every downstream step easier.
Build a place to pin decisions. The api-spec QA step (front-qna or backend-request-checklist) is the one that always costs more to skip than to run. One page is enough, even for small features.
Split spec and plan. Fuse 'what and why' with 'how, at the file level', and the plan bloats until the AI loses mid-plan context. Keep plan tasks at eight or fewer.
Markdown is the lightest format that satisfies humans and AI at the same time. That's why we ended up here, for git history and stable AI input, rather than richer views.
I used to think we ran to markdown because we were short on people. After a few rounds through the cycle, I realized it's actually the other way around: we can run with this few people because there's more we can trace. A good workflow leaves what we decided behind even after the interview ends, and that residue becomes the starting point for the next interview.
Thank you for reading this far.
INSIK HWANG
BAS KOREA · Frontend Engineer