그 부분 어떻게 하기로 했죠? — 단 둘뿐인 개발팀이 마크다운으로 회의를 줄인 이야기
FE 1명·BE 1명 팀이 슬랙 DM·노션·메모를 끊고 인터뷰 음성에서 슬랙 공지까지 한 레포 마크다운으로 잇기까지, 세 번의 사고가 만든 13단계 사이클의 기록입니다.
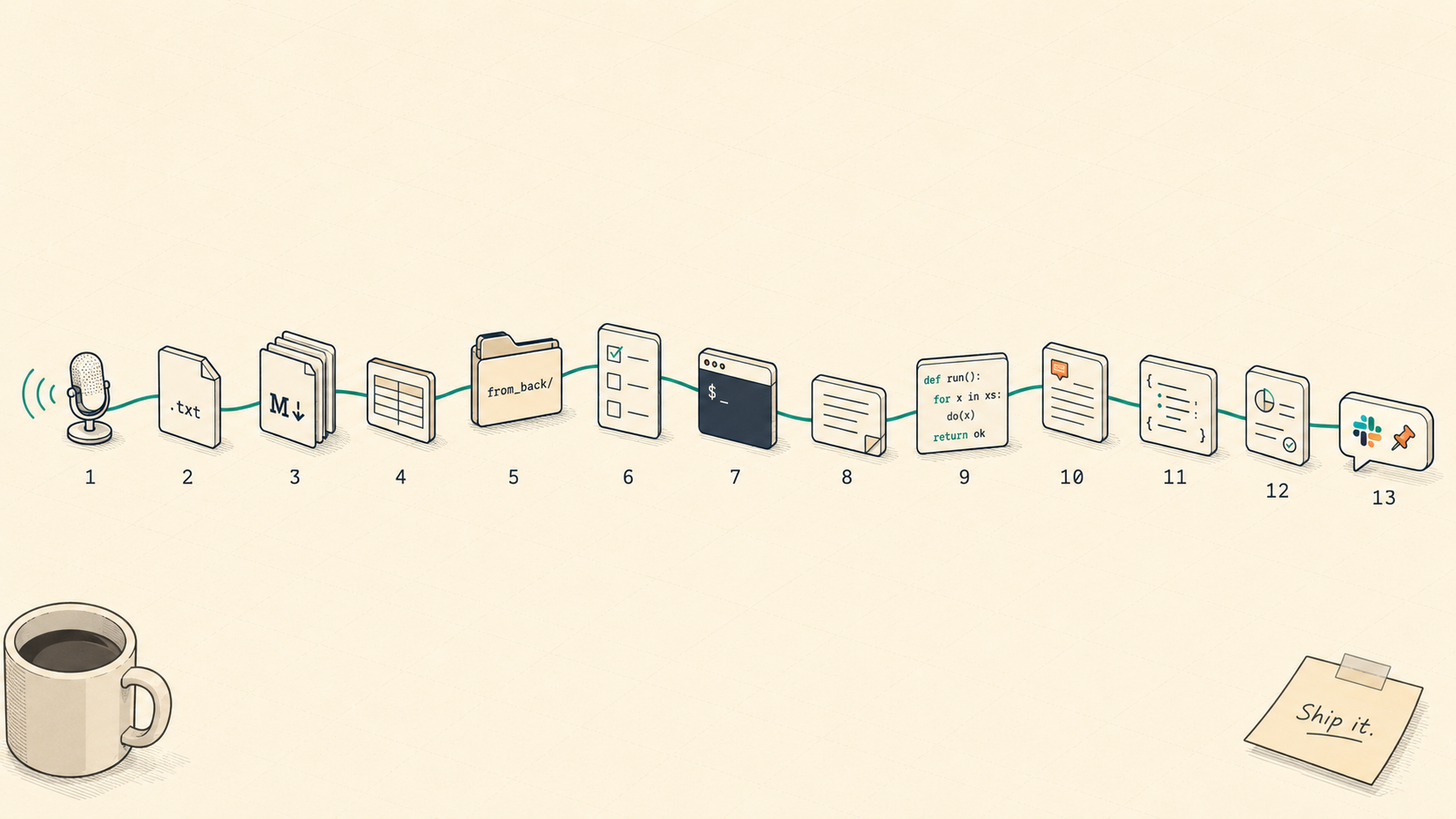
FE 한 명, BE 한 명. 이 두 사람짜리 개발팀이 인터뷰 한 시간 분량의 음성에서 출발해 운영 슬랙 공지까지 가는 길을, 한 레포의 마크다운으로만 잇는 이야기입니다. 이 글은 코드가 아니라 워크플로우 이야기입니다. 우리 팀이 칠판이 아니라 사고에서 배워가며 만든, 추적 가능한 13단계 사이클의 기록입니다.
안녕하세요. BAS KOREA IT팀에서 Flow Mate를 만들고 있는 INSIK입니다.
저희가 만들고 있는 Flow Mate는 Inquiry → Offer → Order → Logistics → Invoice로 이어지는 B2B 수출입·무역 운영 SaaS입니다. 이 흐름이 제품 쪽이라면, 오늘 이야기는 그 제품을 만드는 흐름, 즉 비개발 팀의 발언이 코드와 배포까지 가는 또 하나의 사이클입니다.
저희 개발팀은 두 명입니다. 프론트엔드 한 명, 백엔드 한 명. PM·BA·QA·테크라이터 역할을 두 사람이 겸합니다. 그래서 일찍부터 한 가지가 분명했습니다. 사람의 기억 위에 워크플로우를 얹는 건, 어떤 식으로든 새는 구조라는 점입니다.
이 글이 닿았으면 하는 분들
FE 1~3명짜리 팀에서 PM/BA/QA를 겸하고 계신 분
AI 코딩 에이전트(Claude Code, Codex, Cursor 등)와 협업하면서 입력 컨텍스트가 매번 흔들리는 분
회의마다 '그거 어떻게 하기로 했더라'가 반복되는 것이 불편한 분
1. '그 부분 어떻게 하기로 했죠?'
이 한 문장이 분기마다 회의실에서 들렸습니다. 결론은 분명히 어딘가에서 한 번 났는데, 결론까지 간 추론이 사라진 상태. 다시 회의를 잡고, 다시 결정하고, 다음 분기 회의에서 또 같은 질문을 듣는 사이클이 굳어가고 있었습니다.
당시 요구사항은 이런 곳에 흩어져 있었습니다.
// 출처: 2026-04 사내 회고 메모 (가공)
- 슬랙 #flow-mate-요청: 일주일 단위로 쌓이다 묻힘
- 슬랙 DM: 임원 한 분이 직접 보낸 짧은 질문 (검색이 안 됨)
- 회의 중 구두 요청: '그거 다음에 좀 봐 주세요'
- 노션 페이지 3곳: 누가 작성한 건지 모름
- 카카오톡 단톡방: 회식 자리에서 나온 한 줄 요청
이 풍경의 문제는 단지 검색이 안 된다는 것만이 아니었습니다. 더 큰 문제는 두 가지였습니다. 하나는 같은 요청이 두 채널에 나뉘었을 때 두 번째 받은 사람이 첫 번째 받은 사람의 답변을 못 본다는 것. 다른 하나는, 이걸 그대로 AI 코딩 에이전트에 컨텍스트로 줄 방법이 없다는 것. 슬랙·노션·카카오톡은 한 번에 긁어올 수 없으니, 매번 사람이 기억으로 다시 정리해야 했습니다.
회식 자리에서 누군가 던진 한마디로 이 풍경을 요약할 수 있을 것 같습니다. '사람이 두 명이라서 흩어진 게 아니라, 흩어졌기 때문에 두 명이 부족해 보였습니다.' 채널을 줄이지 않으면, 사람을 늘려도 답이 안 나오는 구조였습니다.
2. 마크다운으로 도망친 이유
처음에는 슬랙 DM이 가장 빨라 보였습니다. 그다음에는 노션이 가장 정리되어 보였습니다. 둘 다 잠깐 보냈습니다. 그 시절은 빨리 끝나는 게 좋다는 걸 두 번째 분기에 알았습니다.
그래서 결국 모든 산출물을 한 git 레포 안의 마크다운으로 옮겼습니다. 이유는 두 가지입니다.
첫째, git history가 곧 의사결정 타임라인이 됩니다. 누가 어느 시점에 어떤 결정을 바꿨는지가 자동으로 남습니다. '그거 어떻게 하기로 했더라'가 즉시 거꾸로 추적됩니다.
둘째, AI 코딩 에이전트의 작업 컨텍스트가 곧 작업 디렉토리입니다. 산출물을 외부에 두면 매번 긁어와서 다시 붙여넣어야 합니다. 같은 레포 안이면 파일 경로 한 줄로 끝납니다. 같은 작업이라도 입력이 슬랙 스크롤 + 회의 메모 + 음성이면 AI의 결과가 흔들리는데, record_data/{날짜}/분석-{이름}.md + docs/from_back/{feature}/api-spec.md면 결과가 안정적입니다.
리치 텍스트 도구의 풍부한 뷰를 포기하는 대신, git history와 AI 입력 안정성을 챙긴 셈입니다. 두 명짜리 팀에는 거의 항상 후자가 맞았습니다.
3. 13단계 사이클: 칠판이 아니라 회차가 굳혀준 것
사이클은 한 번에 그려진 적이 없습니다. 인터뷰 회차가 두세 번 쌓이는 사이에 폴더가 자연스럽게 굳어졌습니다. 우리 레포의 시간선을 거꾸로 추적해 보면, 2026-03-16에 백엔드가 처음으로 api-spec을 폴더 단위로 공유하기 시작했고(docs/from_back/2026-03-16-advance-payments-api-spec/), 2026-03-31에 첫 인터뷰 7건이 클로바노트로 들어왔으며, 2026-04-01에 처음으로 superpowers spec을 끼워 넣었습니다. 4월 27일 Customer-Merge 사건이 front-qna를 표준 산출물로 굳혔고, 2026-05-08에야 사이클 전체가 한 문서로 추출됐습니다(docs/process/development-cycle.md). 한 분기 분의 사고를 한 문서가 압축한 셈입니다.
아래 표가 그 결과로 자리잡은 13단계입니다.
| # | 단계 | 산출물 | 누가 주도 |
|---|---|---|---|
| 1 | 인터뷰 (1:2 또는 N:2) | record_data/{YYYY-MM-DD}/인터뷰-{이름}.txt | FE+BE |
| 2 | 인터뷰별 단독 분석 | 분석-{이름}.md | FE + AI |
| 3 | 통합 작업목록 | 통합-인터뷰-작업목록.md | FE + AI |
| 4 | 우선순위·분야 분리 | FE-단독-작업목록.md 등 | FE (사람 최종 판단) |
| 5 | 작업 순서 결정 + BE 협의 | (슬랙 핑) | FE+BE |
| 6 | 백엔드 api-spec 수신 | docs/from_back/{feature}/api-spec.md | BE |
| 7 | FE 에이전트의 스펙 검토 | front-qna.md / backend-request-checklist.md | FE + AI |
| 8 | spec·plan 생성 | docs/superpowers/specs|plans/{YYYY/MM}/ | FE + AI |
| 9 | 구현 (TDD) | 코드 + Vitest | FE + AI |
| 10 | 수동 QA | docs/superpowers/qa/{YYYY/MM}/ | FE |
| 11 | 배포 (main → release-deploy) | (브랜치 머지) | FE |
| 12 | 슬랙 운영 공지 | 레포 저장 없음 (슬랙 메시지가 곧 산출물) | FE + AI |
| 13 | 사용자 피드백 수집 | 슬랙 스레드 / 다음 인터뷰 | FE+BE |
강조하고 싶은 건 단 하나입니다. 이 13개 노드가 전부 실제 파일/폴더와 1:1 매칭이라는 사실입니다. 추상적인 흐름도가 아니라 산출물 지도입니다. 임의의 운영 화면 한 줄을 들고 와도, 거꾸로 따라가면 어느 인터뷰의 어느 발언에서 출발했는지가 평균 3분 안에 나옵니다. 그게 두 명짜리 팀이 늘어난 사용자 수를 지탱하는 가장 싼 방법이었습니다.
한 가지 안전판도 같이 적어 둡니다. 가벼운 단일 작업이나 긴급 버그까지 이 13단계를 다 돌리지는 않습니다. 한 시간 안에 끝날 수 있는 작업은 5~7단계만 압축하거나, hot-fix는 슬랙·통화 → 코드 → 공지로 곧장 갑니다. 다만 그 경우에도 사후 plan/QA 흔적은 남깁니다. 추적성을 가장 잃기 쉬운 게 바로 fast track이기 때문입니다.
4. 음성에서 마크다운으로, 분석의 다섯 칸
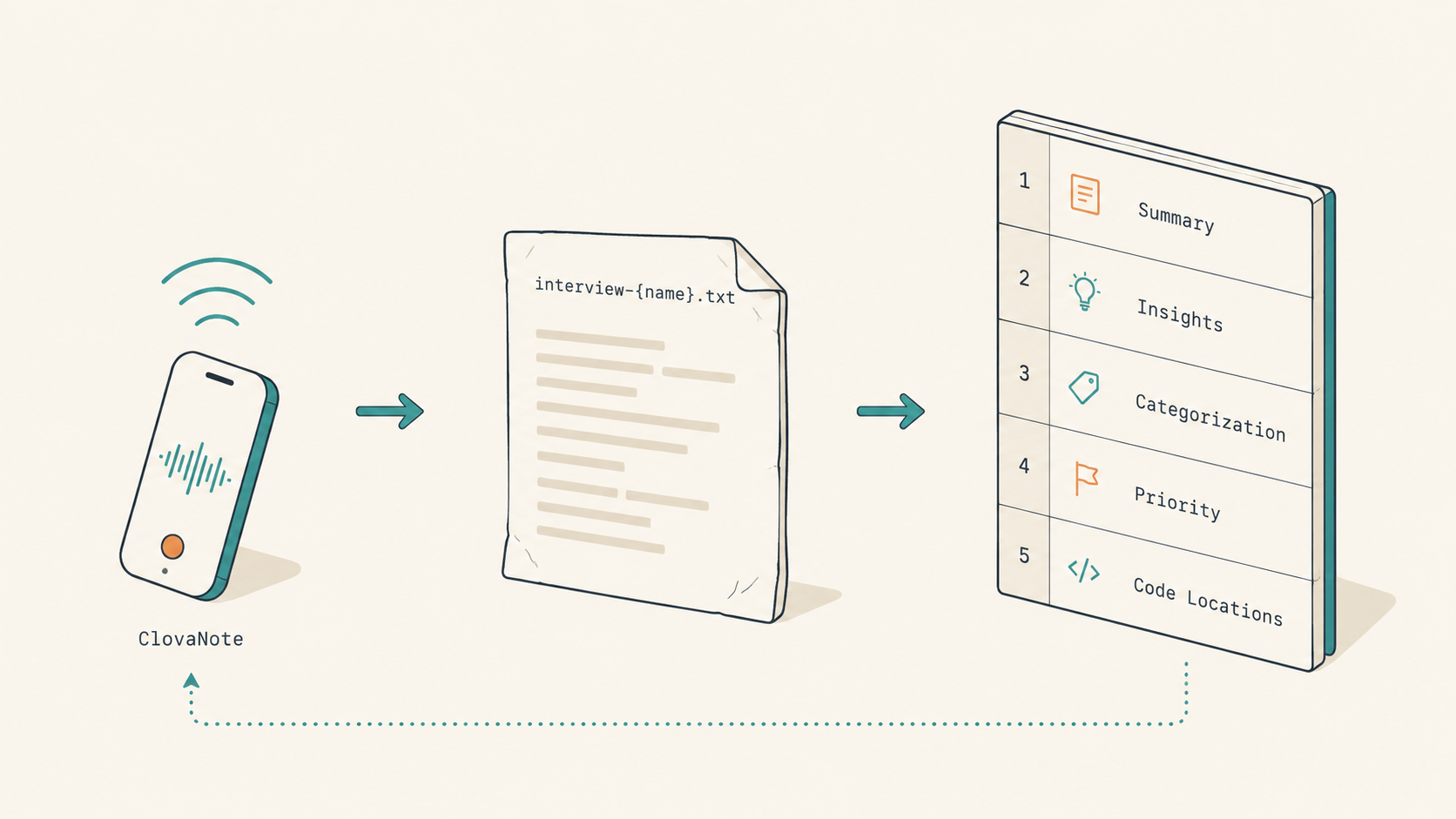
입구는 단순합니다. 비개발 팀(Sales·Logistics·Shared Service)을 1~2주 단위로 1:2(또는 N:2)로 만납니다. 네이버 클로바노트가 자동으로 텍스트 스크립트(.txt)를 뽑아줍니다. 우리는 그 파일을 record_data/{YYYY-MM-DD}/인터뷰-{이름}.txt로 떨궈둡니다. 한 회차에 일곱 명 인터뷰면 일곱 개 파일.
// record_data/2026-03-31/ (실제 폴더 구조, 익명화)
2026-03-31/
├── 인터뷰-{이름A}.txt # 클로바노트 자동 스크립트
├── 인터뷰-{이름B}.txt
├── 인터뷰-{이름C}.txt
├── 인터뷰-{이름D}.txt
├── 인터뷰-{이름E}.txt
├── 인터뷰-{이름F}.txt
└── 인터뷰-{이름G}.txt
여기서 한 가지를 의식적으로 안 합니다. 음성 단계에서는 분류하지 않습니다. 기능 요청, 기존 기능 개선, 버그, 자동화 아이디어가 한 인터뷰 안에 무작위로 섞여 있는데, 사람이 음성을 들으며 동시에 분류하면 분류하느라 어떤 발언은 놓치게 됩니다. 일단 다 받아두고, 분류는 다음 단계의 AI 작업입니다.
다음 단계가 인터뷰별 단독 분석 마크다운입니다. 한 인터뷰가 한 분석 파일로 1:1 매칭됩니다. 일곱 명이면 일곱 개. 합치지 않는 이유는, 합치는 작업은 그다음 단계에서 한 번에 하기 위해서입니다.
각 분석 마크다운은 다섯 칸으로 구성됩니다.
| 섹션 | 내용 |
|---|---|
| 1 | 전체 요약 |
| 2 | 주요 인사이트 (반복된 Pain Point / 임팩트 큰 개선 / 신규 기능 아이디어) |
| 3 | 작업 분류 및 상세 (버그·템플릿·UX·신규 기능) |
| 4 | 우선순위 / 난이도 / 범위(FE·BE·FE+BE) 표 |
| 5 | 코드 위치 후보 (src/... 경로 추정) |
마지막 칸이 핵심입니다. AI에 이 분석 파일을 다음 단계 입력으로 넘기면, 5번 칸의 src/... 경로가 곧장 grep 후보가 됩니다. 구현 단계에서 '어디 있더라'를 검색할 시간이 그만큼 줄어듭니다.
// record_data/2026-03-31/분석-{이름}.md (5섹션 구조의 머리만 발췌, 익명화)
# 인터뷰 분석: Sales팀 한 분 (2026-03-31)
## 1. 전체 요약
...
## 2. 주요 인사이트
- (Pain Point) 인쿼리 목록 검색 옵션이 의뢰 추가 후 초기화됨 (매일 아침 전원이 다시 필터를 잡는 비용)
- (Pain Point) SOA(미수금) FM 데이터와 구글시트의 항목 누락·불일치
- (신규 아이디어) 가격 펜딩 N일 초과 시 자동 'Need Reminder' 상태 전환
## 3. 작업 분류 및 상세
...
## 4. 우선순위 / 난이도 / 범위
| 항목 | 우선순위 | 난이도 | 범위 |
|---|---|---|---|
| 필터 새로고침 초기화 | 상 | 하 | FE |
## 5. 코드 위치 후보
- src/features/inquiry/.../InquiryListFilters.tsx
- src/features/inquiry/hooks/useInquirySearchParams.ts
우선순위·난이도·범위 칸은 일부러 1차 분류로만 두고, 다음 단계에서 사람이 손볼 거라는 사실을 미리 알고 적습니다. 정확도보다 읽기 쉬운 단일 진실(SSOT)이 목표입니다.
5. 통합 작업목록과 '× N' 자동 임팩트 신호
같은 회차의 분석 파일들을 묶어 통합 작업목록 하나로 만듭니다. 여기서 발견한 한 가지가 의외로 큽니다. 같은 요구를 여러 사람이 했을 때, 1건으로 합치고 요청자에 다중 이름을 표시하면 그 자체가 자동 임팩트 신호가 됩니다. 따로 점수를 매기지 않아도 '여러 사람이 같은 말을 했다 = 임팩트가 크다'가 표로 보입니다.
// record_data/2026-03-31/통합-인터뷰-작업목록.md (표 일부 발췌)
| # | 항목 | 요청자 | 우선순위 | 난이도 | 범위 |
|---|---|---|---|---|---|
| 1 | 인보이스 환율 fallback 시각 표시 | Sales × 2 | 상 | 중 | FE+BE |
| 2 | 인쿼리 목록 필터 새로고침 시 유지 | Sales × 3, SS × 1 | 상 | 하 | FE |
| 3 | 거래처 검색 자동완성 디바운스 | Sales × 2 | 중 | 중 | FE |
이 단계만큼은 의식적으로 사람이 최종 판단합니다. AI가 1차 분류한 결과를 보고 '이건 BE가 맞다, 우선순위는 중이 적정하다'를 직접 손봅니다. AI가 멈춰 있어야 하는 순간이 어딘가는 있어야 하고, 우리 팀은 이 단계라고 정해뒀습니다.
회차가 쌓이면 완료 항목이 생기니까, 같은 폴더 안에 미완료-작업목록-{YYYYMMDD}.md를 주기적으로 갱신합니다. 완료 항목은 제거, WIP는 진행률과 블로커를 같이 표기합니다.
// record_data/2026-03-31/미완료-작업목록-20260420.md (헤더만 발췌)
> 2026-03-31 회차의 미완료 작업만 추려서 매주 갱신.
> 완료 항목은 제거, 진행 중 항목은 진행률·블로커를 같이 표기.
| # | 항목 | 상태 | 블로커 |
|---|---|---|---|
| 14 | 인보이스 PDF 로고 교체 | WIP | 디자인팀 로고 확정 대기 |
| 17 | 인쿼리 첨부파일 보존 기간 | DONE | — |
이 갱신 루프가 굴러가기 시작하면, 인터뷰에서 나온 발언이 사일런트하게 사라지지 않습니다.
6. '그 부분 어떻게 하기로 했죠?' (front-qna가 끝낸 한 문장)
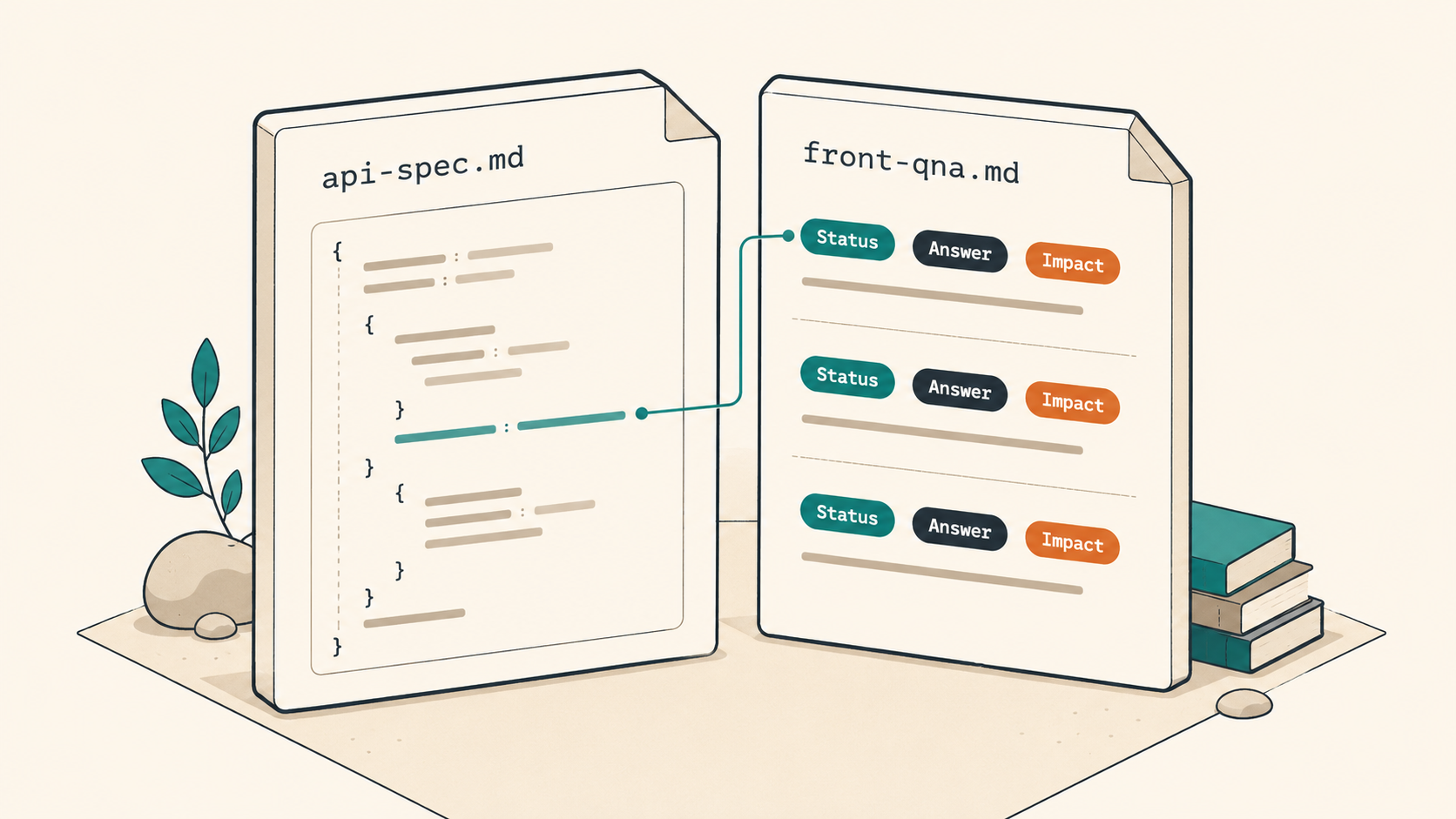
이 한 절이 이 사이클에서 가장 큰 가치를 만든다고 봅니다.
백엔드가 기능 단위로 docs/from_back/{feature}/api-spec.md를 공유하면, FE 쪽 AI 에이전트가 그 문서를 읽고 문제·이슈·질문 목록을 한 파일로 정리합니다. 가벼운 케이스면 front-qna.md에 Q&A로, 큰 기능이면 backend-request-checklist.md에 체크리스트로 정리합니다. 둘 다 같은 폴더 안에 둡니다.
처음에는 이 단계를 종종 건너뛰었습니다. 'api-spec 받았으니 곧장 spec → plan → 구현으로 가자'는 식이었습니다. 2026년 4월 말, Customer-Merge 기능을 그렇게 처리했다가 권한(ADMIN)과 references 응답 스펙이 일치하지 않아 프론트 마이그레이션 흐름을 두 번 다시 짰습니다. 두 번째 구현 직전에 항목 2~5를 front-qna로 다시 정리하면서, 인라인 답변으로 의사결정을 박제했습니다. 이후 작은 기능에도 이 단계를 강제하고 있습니다.
// docs/from_back/2026-04-27-Customer-Merge/front-qna.md (항목 일부 발췌·가공)
## Q2. 병합 대상 references 응답 스펙
- 질문: response의 references[]는 inquiry/order/invoice 모두 포함하나요?
- 상태: 확정
- 답변(BE): inquiry + order + invoice + advance_payment 4종. 페이지네이션 없음.
- 영향: 프론트 마이그레이션 미리보기 카드에 advance_payment 칸 추가 필요.
## Q3. ADMIN 권한 처리
- 질문: 일반 사용자 호출 시 응답 코드는 401인가 403인가?
- 상태: 확정
- 답변(BE): 403 (인증은 됐지만 권한 부족).
- 영향: useApiErrorHandler에서 403일 때 토스트 카피 차별화.
이 패턴이 매끄럽게 도는 데 세 가지가 컸습니다. 첫째, 항목마다 상태(확정/미정/추가질문)가 옆에 박힙니다. 한 번 본 사람이 '여기까지가 끝났구나'를 즉시 알 수 있습니다. 둘째, 답변이 별도 파일로 분리되지 않고 같은 줄 옆에 인라인으로 적힙니다. 답변과 질문이 떨어져 있으면 그 거리만큼 다시 회의가 생깁니다. 셋째, '영향' 줄이 필수입니다. 백엔드 답변이 프론트 어디를 어떻게 바꿀지 한 줄로 남기면, 다음 단계(spec/plan)의 입력으로 그대로 들어갑니다.
사람이 회의로 풀면 '그 부분 어떻게 하기로 했죠?'가 반복되지만, 이 파일이 있으면 양쪽 모두 같은 텍스트를 보고 점검할 수 있고, 결정 근거가 영구히 남습니다. api-spec QA 한 단계를 생략한 비용은, 그 단계를 통과시키는 시간보다 항상 비쌌습니다.
7. spec과 plan을 굳이 분리한 이유

front-qna로 확정된 api-spec을 들고, 통합 작업목록의 한 항목과 인터뷰 발언을 묶어 spec과 plan 두 산출물을 만듭니다. 같은 superpowers 도구 묶음을 쓰지만, 두 파일은 의도적으로 분리되어 있습니다.
| 산출물 | 스킬 | 폴더 | 다루는 것 |
|---|---|---|---|
*-design.md (spec) | superpowers:brainstorming | docs/superpowers/specs/{YYYY/MM}/ | 배경 / Best Practice 근거 / 범위(포함·제외) / UX 설계 / 데이터 흐름 / 엣지 케이스: 무엇을, 왜 |
*.md (plan) | superpowers:writing-plans | docs/superpowers/plans/{YYYY/MM}/ | Goal / Architecture / Tech Stack / File Structure / Task 1..N: 어떻게(파일 단위) |
이 둘을 합치지 않는 이유는 단순합니다. 합치면 plan이 비대해져서 AI 에이전트가 중간 task의 컨텍스트를 잃습니다. '왜 이 코드여야 하는가'의 추론이 중반 이후부터 흔들립니다. 그래서 task가 8개를 넘으면 spec 단계에서 분할합니다. plan 자체를 두 파일로 쪼개기도 합니다.
// docs/superpowers/plans/2026/04/2026-04-03-confirm-logistics-multi-receipt-upload.md
## Task 3. uploadReceiptsSequentially 헬퍼 추가 (TDD)
- [x] failing test: 순차적으로 호출한다 (병렬이 아님)
- [x] failing test: 일부 실패해도 끝까지 시도
- [x] 구현: for-of + try/catch + PromiseSettledResult 반환
- [x] 통과 확인: npx vitest run confirmReceiptUploadUtils.test 통과
- [x] 호출부 교체: LogisticsConfirmModal.tsx
plan의 모든 task가 failing test → 구현 → 통과 확인 3단 체크박스로 구성됩니다. TDD가 강제되지 않아도, 체크박스 1번이 failing test면 자연스럽게 TDD가 됩니다. 그리고 이 체크박스가 진행 상태의 단일 출처입니다. AI 에이전트가 별도 진행 보고를 보내지 않습니다. plan 파일의 모든 체크박스가 - [x]로 채워지면 그 기능은 끝난 것이고, 비어 있는 박스는 곧 잠재적 미완료 작업입니다.
AI의 컨텍스트 한도는 모델의 한도가 아니라, 우리가 한 번에 던지는 정보의 양이라는 걸 이 단계에서 다시 배웠습니다. 줄 수 있다고 다 주는 게 나쁜 선택일 때가 많았습니다.
8. 구현·수동 QA·배포, 짧은 마지막 세 칸
구현은 두 스킬을 골라 씁니다. 같은 세션에서 독립 task를 병렬 디스패치할 수 있을 때는 superpowers:subagent-driven-development, 별도 세션에서 review checkpoint를 두고 단일 흐름으로 진행할 때는 superpowers:executing-plans를 씁니다. 두 스킬 모두 plan 파일의 체크박스를 진행 상황의 단일 출처로 사용합니다.
큰 배포 직전에는 수동 QA 체크리스트를 docs/superpowers/qa/{YYYY/MM}/에 별도 파일로 만듭니다.
// docs/superpowers/qa/2026/04/2026-04-13-ops-release-manual-qa.md (헤더만 발췌)
# 운영 배포 수동 QA (2026-04-13)
## 사전 조건
- 환경: stage.flowmate.bas-korea.com
- 계정: ops-qa-1 (READ_WRITE)
- 데이터: 3월 인보이스 50건, 4월 1주차 인쿼리 12건
## 변경 기능별 관련 코드 경로
- 인쿼리 필터 URL 동기화: src/features/inquiry/hooks/useInquirySearchParams.ts
- 인보이스 환율 표시: src/features/invoice/components/InvoiceRateBadge.tsx
## 시나리오
- [ ] 인쿼리 목록 필터 적용 → 새로고침 → 같은 필터 유지
- [ ] 인보이스 행에서 환율 fallback 발생 시 노란 배지 표시
- [ ] 네트워크 탭: PUT /color 200, DELETE /attachments/{id} 204
QA 체크리스트는 기능별로 짭니다. 날짜별로 짜면 다음 회차에서 같은 시나리오를 또 짜게 됩니다. 사전 조건(환경/계정/데이터), 변경 기능별 코드 경로, 네트워크 탭에서 확인할 요청 경로(PUT /color, DELETE /attachments/{id} 등)까지 한 파일에 같이 둡니다.
배포는 main 머지 후 release-deploy 운영 브랜치로 흐릅니다. 마지막 한 칸이 슬랙 운영 공지입니다. 우리는 이 공지를 일부러 레포에 사본으로 두지 않습니다. 이유는 한 가지입니다. 그 공지의 수신자는 비개발 운영팀이고, 비개발자는 git을 안 보고 슬랙을 봅니다. 진실의 위치를 청자가 있는 곳에 둡니다. 보존이 필요하면 슬랙 영구 링크를 PR 본문이나 머지 커밋에 첨부합니다.
9. TDD는 마크다운에도 적용되는가
코드에는 TDD가 있지만, 마크다운 산출물에는 TDD가 직접 적용되지 않습니다. 대신 단계별 자가검증 체크리스트가 그 역할을 합니다.
| 단계 | 자가 검증 |
|---|---|
| 분석 마크다운 | 5섹션이 다 있는가? 우선순위/난이도/범위가 모든 항목에 매겨졌는가? 코드 위치 후보가 1개 이상 적혔는가? |
| 통합 작업목록 | 같은 요청이 두 줄에 나뉘어 있지 않은가? 요청자에 × N 표기가 있는가? |
| front-qna | 모든 항목에 '상태' + '답변' + '영향' 3줄이 있는가? |
| spec | 범위(포함·제외)가 명시되어 있는가? 엣지 케이스 절이 있는가? |
| plan | 모든 task의 1번 체크박스가 failing test인가? task 개수가 8개 이하인가? |
| QA | 사전 조건(환경/계정/데이터)이 있는가? 네트워크 탭에서 확인할 요청 경로가 있는가? |
테스트는 코드만 검증하는 게 아닙니다. 산출물도 체크리스트의 통과 여부로 검증할 수 있고, 그 체크리스트를 마크다운 끝에 적어두면 다음 회차에서도 같은 기준이 굴러갑니다.
10. 사고가 사이클을 만들었다, 세 번의 복병
지금 보면 깔끔해 보이는 사이클이지만, 세 단계 중 두 단계는 사고 때문에 추가됐습니다. 칠판이 아니라 사고에서 자라난 셈입니다.
| 사건 | 증상 | 회귀 방지 |
|---|---|---|
| Customer-Merge front-qna 생략 (2026-04-27) | 권한 처리(ADMIN)와 references 응답 스펙이 일치하지 않아 프론트 마이그레이션 흐름을 두 번 다시 짬 | 모든 작업에 front-qna 또는 backend-request-checklist 강제. 작은 기능에도 |
| plan task 20개 초과 | 한 plan에 task가 20개 이상 들어가면 AI 에이전트가 중간 task의 컨텍스트를 잃음 | plan task 8개 이상이면 spec 단계에서 분할. plan 자체를 두 파일로 쪼개기도 |
| 인터뷰 분석 미룸 | 음성 파일이 시간이 지나면서 맥락이 휘발. '이 발언이 어떤 분위기였더라'가 사라지면 우선순위가 흔들림 | '48시간 내 분석' 룰. 미룰 거면 음성을 들으며 한 줄 메모라도 인터뷰 .txt 파일 끝에 박아둠 |
특히 첫 번째 사건이 컸습니다. api-spec.md만 보고 곧장 spec → plan → 구현으로 진입했다가, 두 번째 구현 직전에 항목 2~5를 front-qna로 다시 정리하면서 인라인 답변으로 의사결정을 박제했습니다. 이후 작은 기능에도 이 단계를 강제하고 있습니다.
세 번째 사건도 짚어 둘 만합니다. AI는 음성을 해석하지 않습니다. 우리가 음성에서 텍스트로 옮긴 그 시점의 맥락까지가 입력입니다.
11. 도입 후, '그 부분 어떻게 하기로 했죠?'가 사라진 자리
| 지표 | Before | After |
|---|---|---|
| '그 부분 어떻게 하기로 했죠?' 회의 | 주 1~2회, 매번 10~20분 | 거의 사라짐 (front-qna로 즉시 점검) |
| 운영 화면 한 줄 → 인터뷰 발언 추적 | 추적 불가 또는 30분~수 시간 | 평균 3분 안에 거꾸로 따라감 |
| 신규 합류자 온보딩 | 코드만 보고 왜를 추정 | record_data/ → docs/from_back/ → docs/superpowers/ 순서로 읽으면 인터뷰 발언 수준까지 거슬러 이해 |
| AI 컨텍스트 토큰 | 매 회차 슬랙·노션을 다시 긁어 컨텍스트로 태움 | 단계별 입력 파일만 컨텍스트로 전달 |
| 요구사항 누락 | 분기마다 기억나는 요청만 작업 | 통합 → 우선순위 → 미완료 갱신 루프로 사일런트 유실 차단 |
사이클이 안정되고 나서 가장 먼저 사라진 건, 매 분기 회의실에서 듣던 그 한 문장이었습니다. front-qna에 인라인으로 박힌 답변과 영향 줄이 회의 대신 점검 자료가 되면서, 같은 질문이 거의 다시 나오지 않습니다.
두 번째 변화는 임의의 운영 화면 한 줄을 들고 와도, plan → spec → api-spec → 인터뷰 발언까지 평균 3분 안에 거슬러 올라간다는 점입니다. 신규 합류자가 있다면 record_data/ → docs/from_back/ → docs/superpowers/ 순서로 읽으면, 왜 이 코드가 이런 모양인지를 인터뷰 발언 수준까지 거꾸로 이해할 수 있습니다.
세 번째는 AI 비용입니다. 단계별 입력 파일만 컨텍스트로 주면 되기 때문에, 같은 컨텍스트를 매번 다시 태우지 않습니다. 슬랙 스크롤이나 노션 페이지를 매 회차 긁어와 토큰으로 변환하던 비용이 같이 줄었습니다.
화면 한 줄을 보고 왜 이 코드인지 답할 수 있다는 것은, 두 명짜리 팀이 늘어난 사용자 수를 지탱하는 가장 싼 방법이었습니다.
12. 우리가 쓰는 도구·스킬 한 장
| 단계 | 도구 / 스킬 |
|---|---|
| 인터뷰 녹음·전사 | 네이버 클로바노트 (화자 분리·요약 보조) |
| 인터뷰 분석·통합·분류 | Claude Code (claude-opus-4-7) |
| 백엔드 스펙 검토 | Claude Code (backend-request-checklist.md / front-qna.md 작성) |
| 스펙 작성 | superpowers:brainstorming |
| 계획 작성 | superpowers:writing-plans |
| 구현 | superpowers:subagent-driven-development 또는 superpowers:executing-plans |
| 단위 테스트 | Vitest (/** @vitest-environment jsdom */ DOM 사용 시 필수) |
| 수동 QA | 자체 체크리스트 + 네트워크 탭 |
| 배포 공지 | release-announcement 스킬 (일회성 출력 → 슬랙 게시) |
| 커밋 메시지 | commit-message 스킬 (Conventional Commits) |
13. 마무리: 사람이 적어서 도망친 게 아니었습니다

오늘 이야기의 뼈대를 다시 추리면 네 가지입니다.
요구 채널을 줄이세요. 슬랙·노션·DM·메모를 그대로 두면 사람을 늘려도 새는 구조가 됩니다. 인터뷰 한 시간 + 클로바노트 .txt 한 개를 단일 입구로 묶으면, 이후 모든 단계가 그 위에서 안정적으로 굴러갑니다.
결정 근거를 박제할 곳이 필요합니다. api-spec QA(front-qna 또는 backend-request-checklist) 한 단계는 생략한 비용이 항상 더 비쌌습니다. 작은 기능에도 한 페이지면 됩니다.
spec과 plan은 분리하세요. '무엇을, 왜'와 '어떻게(파일 단위)'를 합치면 plan이 비대해져서 AI가 중간 task에서 컨텍스트를 잃습니다. plan task는 8개 안으로.
마크다운은 사람과 AI 두 청자를 동시에 만족시키는 가장 가벼운 포맷입니다. 그래서 우리는 git history와 AI 입력 안정성을 챙기는 쪽으로 갔습니다.
처음에는 사람이 적어서 마크다운으로 도망친 줄 알았습니다. 그런데 사이클이 한 바퀴 돌고 보니, 사실은 추적할 수 있는 것이 늘어났기 때문에 사람이 적어도 굴러간다는 걸 알게 됐습니다. 좋은 워크플로우는 인터뷰가 끝난 뒤에도 어떤 결정을 했는가가 남고, 그게 다음 인터뷰의 시작점이 됩니다.
긴 글 읽어주셔서 감사합니다.
INSIK HWANG
BAS KOREA · Frontend Engineer